#07장 병렬 데이터 처리와 성능
Raoul-Gabriel Urma 저, 우정은 역 「Modern Java in Action, 2019」를 읽고 정리하였습니다.
이 장에서는
병렬 스트림으로 데이터를 병렬 처리하기
병렬 스트림의 성능 분석
포크/조인 프레임워크
Spliterator로 스트림 데이터 쪼개기
7.1 병렬 스트림
parallelStream(): 스트림 요소를 청크로 분할된 병렬 스트림 생성된다.
사례: n까지의 숫자 합계
무한 스트림 생성
n으로 스트림 크기 제한
더하는 리듀싱 작업 수
public long sequentialSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.reduce(0L, Long::sum);
}전통적인 방식
7.1.1 순차 스트림을 병렬 스트림으로 변환하기
이런 걱정 NO
결과 변수를 어떻게 동기화해야?
몇개의 스레드를 사용해야?
숫자는 어떻게 생성?
생성된 숫자는 누가 더할까?
parallel() 메소드 추가
여러 청크로 분할
sequential() 도 있다.
번갈아 사용할 경우, 마지막 호출이 전체 파이프라인에 영향을 미친다.
pararellel이 마지막 호출됬으니.
7.1.2 스트림 성능 측정
3가지 기법 성능 비교
반복형, 순차리듀스형, 병렬 리듀싱
도구: JMH (Java Microbenchmark Harness)
어노테이션 방식으로 측정 심플
설정
XML 설정
어노테이션 추가
실행 환경
i7-4600u 2.1GHz 쿼드 코어
기존 반복형 (iterativeSum)
시간: 3.278 ms
순차리듀스형 (sequentialSum)
시간: 121.843 ms
병렬 리듀싱 (parallelSum)
시간: 604.059 ms
결과를 보면,
for문이 가장 빠르게 나왔다.
의외의 결과가 나온 이유
박싱된 객체가 만들어지므로, 더하려면 언박싱을 해야한다.
반복 작업은 병렬로 수행할 수 있는 독립 단위로 나누기가 어렵다.
이처럼 병렬 프로그래밍은 함정이 숨어있다.
더 특화된 메서드 사용
LongStream.rangeClosed() 장점
기본형 long을 직업 사용하므로, 박싱과 언박싱 오버헤드 x
쉽게 청크로 분할할 수 있는 숫자 범위를 생성 해준다.
예, 1~20을 1-5, 6-10, 11-15, 16-20 로 분할
아래 코드 걸린 시간: 5.315 ms
기존 iterate 메서드 보다 속도가 빠르다.
어떤 알고리즘 병렬화를 선택하는 것보다 적절한 자료구조 선택이 중요하다.
하지만, 병렬 스트림을 적용하면 어떻게 될까?
아래 코드 걸린 시간: 2.677 ms
드디어 빠른 병렬 리듀싱을 만들었다.
주의할 점
서브스트림을 서로 다른 스레드의 리듀싱 연산을 할당하고 다시 합치는데, 즉, 멀티코어간 데이터 이동은 비싸다. 이부분을 주의해야 한다.
7.1.3 병렬 스트림의 올바른 사용법
퀴즈: 다음 코드의 문제는 무엇일까?
답: total이 공유된 상태이기에 데이터 레이스가 발생 할 수 있어, 아래 코드는 병렬 스트림을 사용할 수 없는 코드이다.
7.1.4 병렬 스트림 효과적으로 사용하기
1000개 이상 요소일 때 병렬 스트림 사용 -> 이런 기준은 없다
그러나, 수량적 힌트 사용은 도움
벤치마크로 직접 측정
박싱 주의
IntStream, LongStream, DoubleStream 사용 추천
순차 스트림보다 병렬 스트림에서 성능이 떨어지는 연산
예: limit(), findFirst()
파이프라인 연산 비용 고려
N*Q
N: 처리할 요소수
Q: 하나 요소 처리에 드는 비용
Q가 높을 경우, 병렬 스트림 사용시 개선될 확률이 높다.
소량 데이터에서 병렬 스트림은 도움 x
자료구조가 적절한지 확인
LinkedList 보단 ArrayList가 효율적으로 분할 가능. 왜? LL은 모든 요소 탐색해야 하니.
스트림의 특성과 파이프라인의 중간연산이 스트림의 특성을 어떻게 바꾸는지에 따라 분해 과정 성능이 달라질 수 있다.
쉽게 말해, SIZED 스트림은 같은 크기로 분할 가능한데, 필터연산이 있으면 스트림 길이를 예측할 수 없으므로 병렬 처리 할수있을지 알 수 없다.
최종 연산의 병합 과정 비용을 살펴보라.
7.2 FORK/JOIN 프레임 워크
병렬 스트림이 수행내되는 내부 인프라 구조를 알기위해 이 프레임워크를 알아야 한다.
과정: 재귀적으로 작은 작업으로 분할 -> 서브 태스크 결과를 합친다.
포크 의미: 다른 스레드를 만드는것.
7.2.1 RecursiveTask 활용
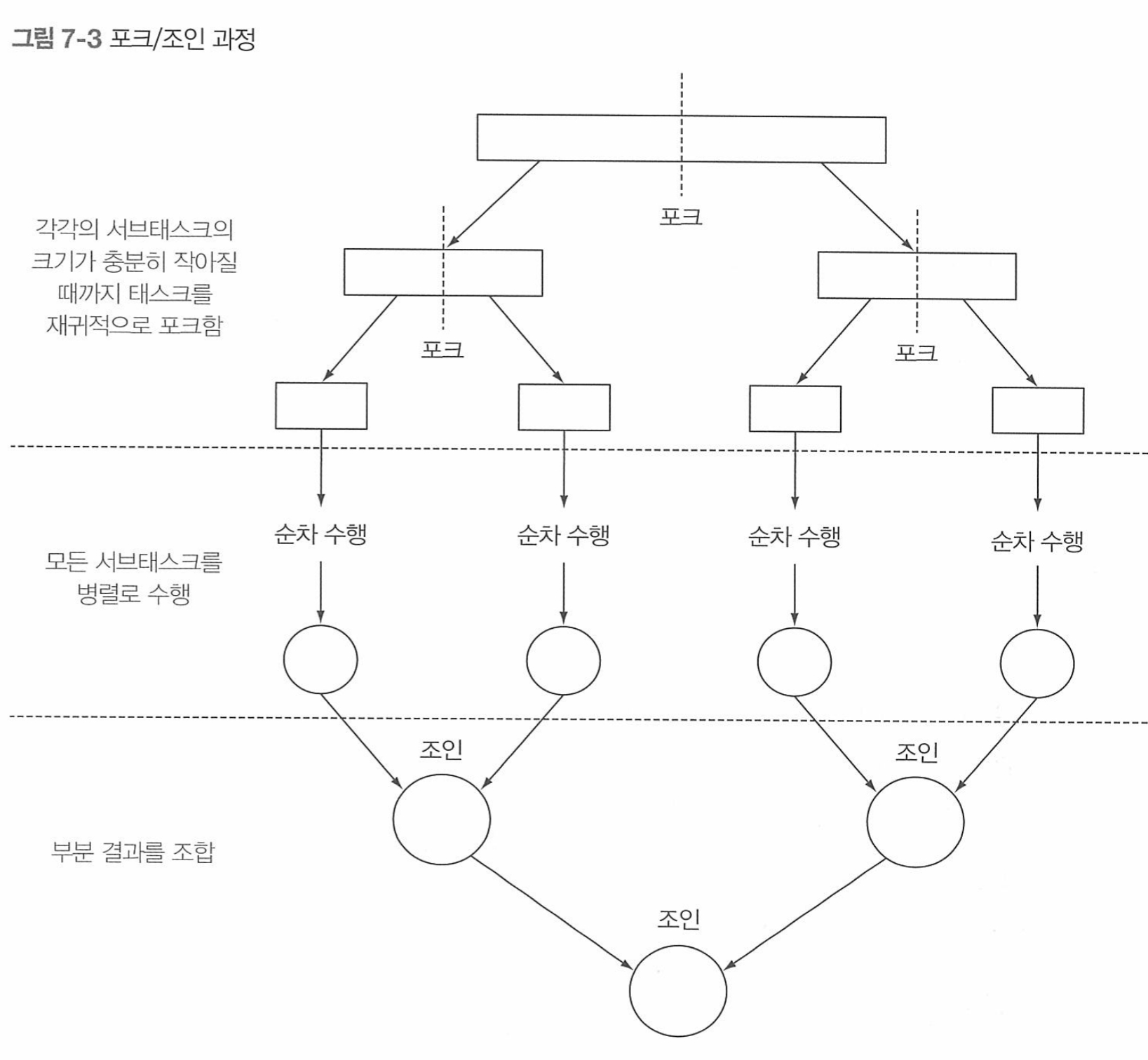
필요한 과정은 아래 코드와 같다
포크/조인 프레임워크를 이용한 병렬 합계 수행
ForkJoinSumCalculator 실행
ForkJoinPool은 스레드 풀로 작업자 스레드에 분산 할당하는 ExecutorService를 구현하고 있다.
N: 100,000 경우
10개로 쪼갠 후
시작점은 1~10,000 ...
이런식으로 작동되겠습니다.
ForkJoinSumCalculator 100,000
Left: ForkJoinSumCalculator 1~50,000
Left: ...
Right: ...
Right: ForkJoinSumCalculator 50,001~100,000
Left: ...
Right: ...
TIP: 일반적으로 애플리케이션에서는 ForkJoinPool을 1개의 싱글턴으로 만들고 재사용한다.
7.2.2 포크/조인 프레임워크 제대로 사용하기
퀴즈: 왜 한쪽에서만 fork()를 쓰고, 다른 한쪽은 compute()를 사용했을까?
각각 사용이 효율적이다. -> 두 서브태스크의 한 태스크에 같은 스레드를 사용할 수 있음으로 불필요한 태스크 할당의 오버헤드 방지한다.
포크/조인에서 병렬 계산시 디버깅이 어려운 이유는?
fork 라 불리는 다른 스레드에서, compute를 호출함으로 스택 트레이스가 도움되지 않는다.
팁, 효율적 성능을 위해, 서브태스크의 실행시간 > forking 시간
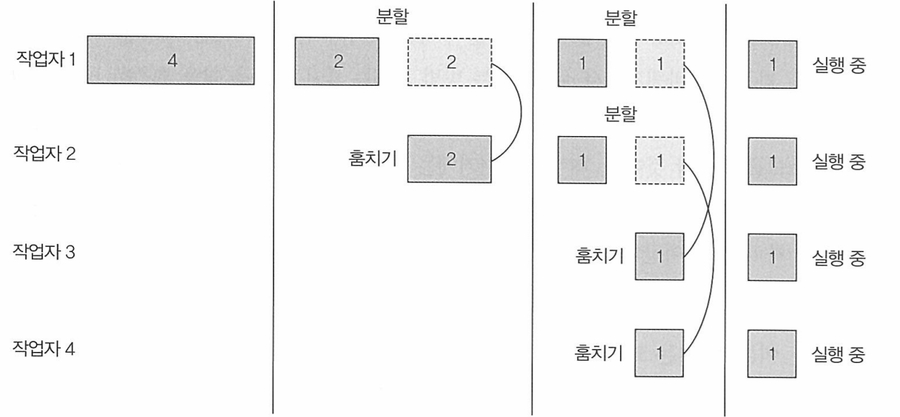
7.2.3 작업 훔치기 (work stealing)
N = 1000만 경우 -> 1000개 이상 서브 태스크로 쪼개질것
퀴즈: 코어가 이렇게 많지도 서브태스크를 많이 쪼개는게 좋은걸까?
답: 코어수와 관계없이 적절한 크기로 분할된 많은 태스크를 포킹하는 것은 바람직하다.
작업 훔치기는 분할 기법이 효율적이지 않을때 발생하는 문제를 해결해준다.
역할: ForkJoinPool의 모든 스레드를 공정하게 분할
작동과정
Doubly LinkedList 사용
하나의 스레드 작업이 끝나면, 링크드리스트 큐에 기다리는 다른 작업에게 넘겨준다.
한 작업자가 태스크를 분할했을때, 다른 작업자가 훔치기 가능
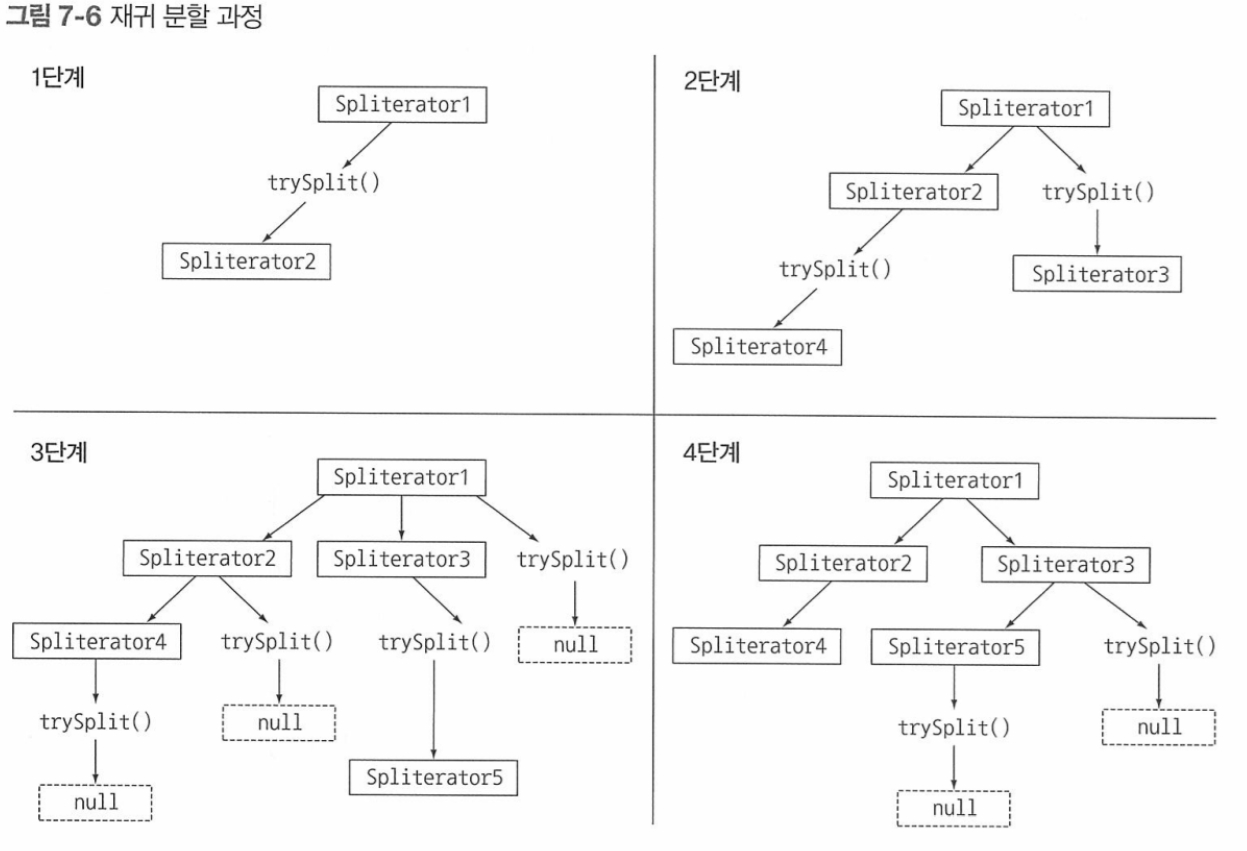
7.3 Spliterator 인터페이스
Spliterator (spliter + iterator): 자동으로 스트림을 분할해준다. (자바 8에서 등장)
결론: ~ "기존 Stream으로는 번거로운 작업들을 좀 더 쉽게 처리 할 수 있어, 잘 쓰기만 한다면 많이 활용 할 수 있을것 같습니다."
7.3.1 분할 과정
null은 더이상 분할 불가 의미
7.3.2 커스텀 Spliterator 구현하기
기존 반복형을 이용해 단어수를 구할 경우
WordCounter 병렬로 수행
아래 코드 병렬 X, 그냥 스트림 처리시
266~277쪽이 없네요...ㅜㅜ
아래 코드 병렬 O
기대했던 19 words 가 아닌 다른 값...
이유: 원래의 문자열을 원래의 위치에서 둘로 나누다보니 예상치 못하게 하나의 단어를 둘로 계산하는 상황이 왔다. 문슨말?????? 즉, 순차 스트림을 병렬 스트림으로 바꿀때 분할 위치에 따라 잘못된 결과가 나올 수 있다.
해결법: 단어를 중간이 아닌 끝나는 위치를 기준으로 분할하자.
해결하기 위해, Spliterator 를 사용할때가 왔다!
7.4 마치며
내부 반복을 이용하면, 명시적으로 다른 스레드를 사용하지 않고도 스트림을 병렬 처리 가능
항상 병렬 처리가 빠른것은 아님. (직접 성능 체크 필수)
처리할 데이터가 많거나 각 요소 처리 오랜시간 걸릴때 병렬스트림 추천
성능을 위해, 기본형 특화 스트림 사용 권장
포크/조인은 서브태스크로 분할 후 각 스레드에서 처리후 머지
Spliterator는 탐색하려는 데이터를 포함하는 스트림을 어떻게 병렬화할 것인지 정의
Last updated