48. 스트림 병렬화는 주의해서 적용하라
주류 언어 중, 동시성 프로그래밍 측면에서 자바는 항상 앞서갔다. 처음 릴리스된 1996년 스레드, 동기화, wait/notify 지원 자바 5, 동시성 컬렉션인 java.util.concurrent 라이브러리와 실행자(Executor) 프레임워크 지원 자바 7, 고성능 병렬 분해(parallel decom-position) 프레임워크 포크-조인 패키지 추가 자바 8, parallel 메서드만 한 번 호출하면 파이프라인을 병렬 실행할 수 있는 스트림 지원
자바로 동시성 프로그램을 작성하기가 점점 쉬워지고는 있지만, 올바르고 빠르게 작성하는 일은 어렵다.
동시성 프로그래밍을 할 때는 안전성(safety)과 응답 가능(liveness) 상태를 유지하기위해 애써야한다.
파이프라인에서 만들어진 모든 원소를 하나로 합치는 작업인 축소(reduction)는 스트림 병렬화에서 중요한 종단 연산이다.
병렬 스트림이 수행내되는 내부 인프라 구조를 알기위해 Fork/Join 프레임워크를 알아야 한다.
Stream reduce의 주요 개념
Identity, Accumulator, Combiner
Identity: 초기값
Accumulator
Arrays.asList(1, 2, 3, 4, 5, 6) .stream() .reduce(0, (subtotal, num) -> subtotal + num);Combiner
스트림이 병렬로 실행될 때 Java 런타임은 스트림을 여러 하위 스트림으로 분할합니다. 이러한 경우, 우리는 서브스트림의 결과를 단일 결과로 결합하는 함수를 사용해야 합니다. 즉, combiner.
Arrays.asList(1, 2, 3, 4, 5, 6) .parallelStream() .reduce(0, (a, b) -> a + b, Integer::sum);Accumulator와 Combiner 차이는?
규약 자료
Stream의 reduce 연산에 건네 지는 accumulator와 combiner 함수는 associative, non-interfering, stateless 해야한다.
associative - 피연산자의 순서에 영향을 받지 않습니다
non-interfering - 작업이 기존 데이터에 영향을 미치지 않습니다.
stateless and deterministic - 작업에 상태가 없고 주어진 입력에 대해 동일한 출력을 생성합니다.
스트림 병렬화가 어려운 사례
메르센 소수란?
소수들 중 '2의 n승 빼기 1'로 표현되는 소수
예
소수: 2, 3, 5, 7, 11, ...
메르센 소수: 3, 7, 31, 127, ...
다음 코드가 병렬화가 가능할지 생각해보자.
숫자 범위를 10k 단위로 쪼개서 계산?
parallel() 을 붙혀보면, 10초 정도면 끝나는 프로그램이 cpu 90%를 차지하다가 1시간이 지나 강제 종료가 된다
오작동하여 safety를 잃었고, 응답 없어 종료되어 liveness를 잃었다.
스트림 라이브러리가 이 파이프라인을 병렬화하는 방법을 찾지 못했다
병렬화가 안되는 코드 2가지 특징
데이터 소스가
Stream.iterate사용중간 연산으로
limit을 사용아래 코드는 두 문제 모두 지님
스트림 병렬화에 좋은 사례
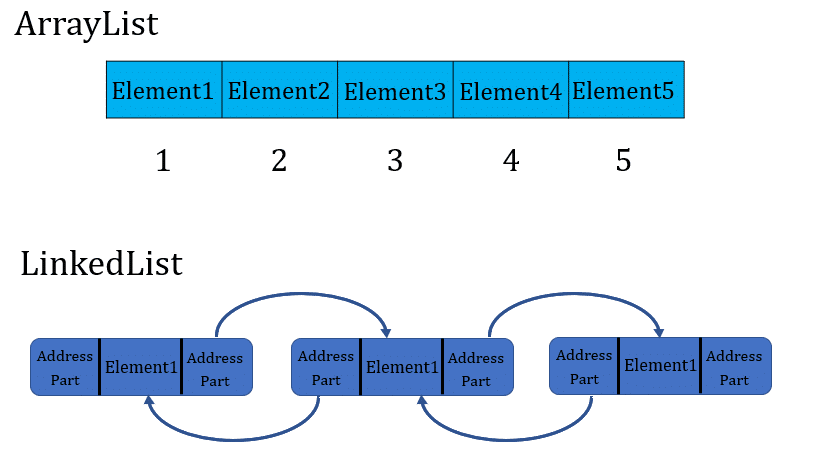
대체로 스트림의 소스가 ArrayList, HashMap, HashSet, ConcurrentHashMap의 인스턴스거나 배열, int 범위, long 범위일 때 병렬화의 효과가 가장 좋다.
좋은 이유?
해당 자료구조들은 원소들을 순차적으로 실행할 때
참조 지역성(locality of reference]이 뛰어나다. (이웃한 원소의 참조들이 메모리에 연속해서 저장되어 있다는 뜻)해당 자료구조들은 데이터를 원하는 크기로 정확하고 손쉽게 나눌 수 있어, 일을 다수의 스레드에 분배하기 좋다는 특징이 있다. (나누는 작업은 Spliterator가 담당하며, Splitertor 객체는 Stream이나 Iterable의 Spliterator 메서드로 얻어올 수 있다.)
Spliterator - 자세한 것은 모던자바 7장 참고
{kind=link}
참조 지역성이 낮으면 스레드는 데이터가 주 메모리에서 캐시 메모리로 전송되어 오기를 기다리며 시간을 낭비한다. 따라서 참조 지역성은 다량의 데이터를 처리하는 벌크 연산을 병렬화할 때 중요하다. 참조 지역성이 가장 뛰어난 자료구조는 기본 타입의 배열이다 (예, new int[]). 참조가 아닌 데이터 자체가 메모리에 연속해서 저장되기 때문이다.
직접 구현한 Stream, Iterable, Collection이 병렬화의 이점을 제대로 누리게 하고 싶다면 Spliterator 메서드를 반드시 재정의하고 결과 스트림의 병렬화 성능을 강도 높게 테스트하라. (재정의 예시)
스트림 안의 원소 수와 원소당 수행되는 코드 줄 수를 곱해서
최소 수십만은 되어야 성능 향상을 맛볼 수 있다.보통 병렬 스트림 파이프라인도 공통의 Fork/Join 풀에서 수행되므로 (같은 스레드 풀 사용), 잘못된 파이프라인 하나가 시스템의 다른 부분의 성능까지 악영향을 줄 수 있다. (무슨말?)
스트림 파이프라인 병렬화가 효과를 발휘하는 사례
LongStream, IntStream 과 같은 사례는 스트림 파이프라인 병렬화 효과를 제대로 발휘할 수 잇다.
기본형 long을 직업 사용하므로, 박싱과 언박싱 오버헤드 없고, 쉽게 청크로 분할할 수 있는 숫자 범위를 생성 해준다.
예, 1~20을 1-5, 6-10, 11-15, 16-20 로 분할
무작위 수 스트림과 병렬화
무작위 수들로 이뤄진 스트림을 병렬화하려거든 ThreadLocalRandom, Random 보다는 SplittableRandom 인스턴스를 사용하자.
SplittableRandom은 이를 위해 설계된 것이라 병렬화하면 성능이 선형으로 증가한다.
결론
병렬화를 해서 성능이 더 안좋을 수 있으니 직접 구현 후 성능체크를 해보자.
적절한 자료구조 사용 (ArrayList Yes, LinkedList No)
병렬에서 기본자료형 스트림 사용 추천 (IntStream)
서브태스크의 실행시간이 forking 시간 보다 오래걸려야 한다.
코어가 이렇게 많지도 서브태스크를 많이 쪼개는게 좋은걸까? 코어수와 관계없이 적절한 크기로 분할된 많은 태스크를 포킹하는 것은 바람직하다.
Last updated